Tree structure in SQL
2014-09-12
開發應用程式時,樹狀結構的資料其實很常見,只是當需要將這些資料用 SQL 資料庫儲存下來時,就會發現問題忽然複雜了許多;能保存資料間的階層關連性還不夠,還必須考慮到各類查詢和修改的效能。前陣子讀了 SQL Antipatterns: Avoiding the Pitfalls of Database Programming;在這本書裡面,作者就儲存樹狀結構的幾種 pattern 做了介紹,並比較每個方式的優缺點。我覺得這是很實用的技巧,所以這篇文章就以書中的資料為主,來介紹不同的實作方式。
以下的範例都是以書中的例子改寫成 MySQL 的程式 (不包括 common table expression,因為 MySQL 不支援),並且附上建立資料的 query,方便自己實驗時使用。例圖部份是以書中的圖修改的。
前置
假設現在要做 bug-tracking 軟體的評論功能,使用者除了可以在 bug 內發表評論外,還可以回應特定的評論。可能會像這個樣子:
Fran: 為什麼會有這個 bug ?
├─ Ollie: 我想應該是 null pointer。
│ └─ Fran: 不是,我確認過了。
│
└─ Kukla: 應該要去檢查錯誤資料。
├─ Ollie: 對,這是個 bug。
│
└─ Fran: 請加上個檢查。
└─ Kukla: 加上去後就好了。
在不考慮階層關係的情況下,我們可以用這樣的一張表把每個評論記下來。
CREATE TABLE comments (
comment_id BIGINT UNSIGNED AUTO_INCREMENT PRIMARY KEY,
bug_id BIGINT UNSIGNED NOT NULL,
author TEXT NOT NULL,
comment_text TEXT NOT NULL,
);
資料會長這個樣子:
comment_id bug_id author comment_text
--------------------------------------------------
1 1234 Fran 為什麼會有這個 bug ?
2 1234 Ollie 我想應該是 null pointer。
3 1234 Fran 不是,我確認過了。
4 1234 Kukla 應該要去檢查錯誤資料。
5 1234 Ollie 對,這是個 bug。
6 1234 Fran 請加上個檢查。
7 1234 Kukla 加上去後就好了。
Adjacency List
這個 pattern 應該是最常見也最容易實作與理解的方式:藉由讓每一筆 comment 記住自己的 parent 來維持住階層的關係。在此增加了 parent_id 這個欄位。
CREATE TABLE comments (
comment_id BIGINT UNSIGNED AUTO_INCREMENT PRIMARY KEY,
bug_id BIGINT UNSIGNED NOT NULL,
parent_id BIGINT UNSIGNED, -- 新欄位
author TEXT NOT NULL,
comment_text TEXT NOT NULL,
FOREIGN KEY (parent_id) REFERENCES comments(comment_id) ON DELETE CASCADE
);
而資料看起來會長這個樣子:
comment_id parent_id author comment
---------------------------------------------------------
1 NULL Fran 為什麼會有這個 bug ?
2 1 Ollie 我想應該是 null pointer。
3 2 Fran 不是,我確認過了。
4 1 Kukla 應該要去檢查錯誤資料。
5 4 Ollie 對,這是個 bug。
6 4 Fran 請加上個檢查。
7 6 Kukla 加上去後就好了。
查詢
我們可以用 Join 靠一次查詢拿到下一階的資料
SELECT c1.*, c2.* FROM comments c1
LEFT OUTER JOIN comments c2 ON c2.parent_id = c1.comment_id
WHERE c1.comment_id = 1;
可是想要一口氣查一階以上時,就得再 Join 下去
SELECT c1.*, c2.*, c3.*, c4.*
FROM comments c1 -- 第一階
LEFT OUTER JOIN comments c2
ON c2.parent_id = c1.comment_id -- 第二階
LEFT OUTER JOIN comments c3
ON c3.parent_id = c2.comment_id -- 第三階
LEFT OUTER JOIN comments c4
ON c4.parent_id = c3.comment_id -- 第四階
WHERE c1.comment_id = 1;
而且這種方式在階層數不固定時,就還要再想辦法動態產生 SQL。不然就是得要分次查詢。
部份資料庫如 PostgreSQL 有支援 Common Table Expression,可以使用 WITH 語法做到遞迴查詢,達成一次呼叫的目的。
WITH comment_tree
(comment_id, bug_id, parent_id, author, comment_text, depth)
AS (
SELECT *, 0 AS depth FROM comments
WHERE parent_id IS NULL
UNION ALL
SELECT c.*, ct.depth+1 AS depth FROM comment_tree ct
JOIN comments c ON (ct.comment_id = c.parent_id)
)
SELECT * FROM comment_tree WHERE bug_id = 1234 WHERE commend_id = 1;
除此之外,一口氣將所有資料讀出來,組成樹狀資料結構後放在 cache 提供查詢也是一種妥協的方式。只是這個方法在資料量大,或者是資料常修改次數高的時候能帶來的效益也有限。
修改
雖然查詢很糟,可是修改樹狀結構的時候倒是十分容易。
增加一筆 comment:
INSERT INTO comments (bug_id, parent_id, author, comment_text)
VALUES (1234, 7, 'Kukla', 'Thanks!');
搬移:
UPDATE comments SET parent_id = 3 WHERE comment_id = 6;
如果有針對外來鍵設定 ON DELETE CASCADE 的話,刪除也是一次做完:
DELETE FROM comments WHERE comment_id = 4;
小結
優點 :
- 實作容易,易於理解。
- 大部份時候修改資料結構都很單純。
缺點 :
- 針對部份樹狀結構做查詢時效能不佳,實作也較麻煩。
Path Enumeration (Materialized Path)
所謂的 Path Enumeration,指的就是將整個樹的路徑列舉出來,舉例來講,像檔案系統路徑 /usr/share/applications 就是一種 Path Enumeration。
在 Adjacency List 中,每一筆 comment 只知道自己上一層的資料,因此在查詢時會花費額外的功夫。Path Enumeration 透過記錄完整路徑的方式,來解決 Adjacency Lists 難以處理的狀況。表格結構上,增加了 path 這個欄位。
CREATE TABLE comments (
comment_id BIGINT UNSIGNED AUTO_INCREMENT PRIMARY KEY,
path VARCHAR(1000), -- 新欄位
bug_id BIGINT UNSIGNED NOT NULL,
author TEXT NOT NULL,
comment_text TEXT NOT NULL
);
資料:
comment_id path author comment
---------------------------------------------------------------------
1 1/ Fran 為什麼會有這個 bug ?
2 1/2/ Ollie 我想應該是 null pointer。
3 1/2/3/ Fran 不是,我確認過了。
4 1/4/ Kukla 應該要去檢查錯誤資料。
5 1/4/5/ Ollie 對,這是個 bug。
6 1/4/6/ Fran 請加上個檢查。
7 1/4/6/7/ Kukla 加上去後就好了。
查詢
靠著 path 的資料,我們可以很輕易地查詢子樹狀結構:
comment 7 的所有父階:
SELECT * FROM comments AS c WHERE '1/4/6/7/' LIKE CONCAT(c.path, '%');
這個查詢會將 1/, 1/4/, 1/4/6/ 三個父階以及自己全部查詢出來。
comment 4 的所有子階:
SELECT * FROM comments AS c WHERE c.path LIKE '1/4/%';
這個查詢會將 1/4/5/, 1/4/6/, 1/4/6/7/ 三個子階及自己全部查詢出來。
由於查詢子樹狀結構變得十分簡單,所以套用 aggregation function 也很直接:
SELECT COUNT(*), author FROM comments AS c WHERE c.path LIKE '1/4/%' GROUP BY c.author;
得到
COUNT(*) author
------------------
1 Fran
2 Kukla
1 Ollie
修改
為了要維護路徑,修改資料時就麻煩了。例如在 comment 7 下一層新增一筆評論:
-- 先新增資料
INSERT INTO comments (author, bug_id, comment_text) VALUES ('Ollie', 1234, 'Good job!');
-- 再更新路徑
UPDATE comments AS c, (SELECT path FROM comments WHERE comment_id = 7) AS c2
SET c.path = CONCAT(c2.path, LAST_INSERT_ID(), '/')
WHERE comment_id = LAST_INSERT_ID();
搬移的話必須要將所有子階的路徑全部 update,由於每一個路徑要更新的值都不一樣,因此需要用到 CASE..WHEN 語法來動態決定更新的值。例如將 comment 4 搬到 comment 2 之下:
UPDATE comments SET path = CASE WHEN path LIKE '1/4/%' THEN REPLACE(path, '1/', '1/2/') END WHERE path LIKE '1/4/%';
刪除的時候因為查詢方便,所以不是問題:
DELETE FROM comments WHERE path LIKE '1/4/%';
小結
優點 :
- 實作容易,易於理解。
- 查詢容易。
缺點 :
- 依賴 LIKE 語法,索引帶來的效能改善受限於語法的使用方式。
- 修改資料時需要維護所有子階的路徑資料。
- 路徑根據資料庫、primary key 長度等條件,可能會遇到長度限制。
- 路徑是自己編碼過的資料,沒有辦法用外來鍵確保資料完整性。
Nested Sets
Nested Sets 是一種藉由記錄樹的 Pre-Order Tree Traversal 順序來達到記錄階層結構的方法。這個方式需要增加以下的欄位:
CREATE TABLE comments (
comment_id BIGINT UNSIGNED AUTO_INCREMENT PRIMARY KEY,
nsleft INTEGER NOT NULL, -- 新欄位
nsright INTEGER NOT NULL, -- 新欄位
bug_id BIGINT UNSIGNED NOT NULL,
author TEXT NOT NULL,
comment_text TEXT NOT NULL
);
nsleft, nsright 指的是在 Pre-Order Tree Traversal 時,第一次和第二次經過此節點的步數。第一次經過時將步字寫在節點左邊,第二次經過時寫在右邊,最後就會形成如下圖所示的樣子。
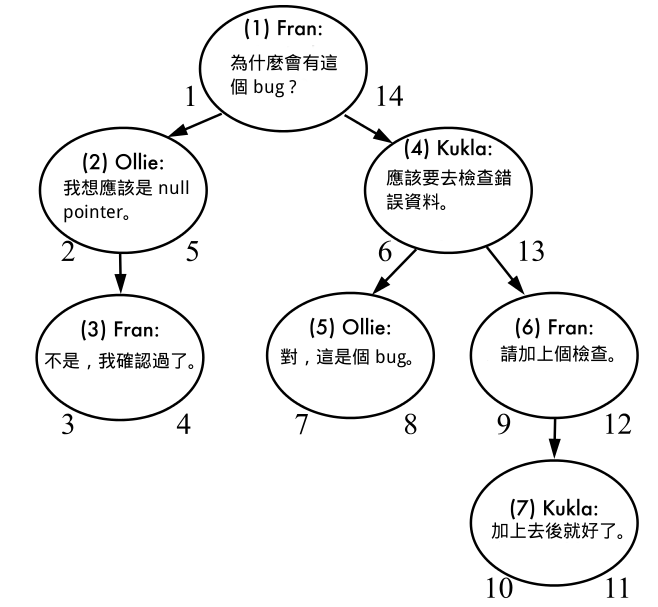
因此資料看起來會是這個樣子:
comment_id nsleft nsright author comment_text
------------------------------------------------
1 1 14 Fran 為什麼會有這個 bug ?
2 2 5 Ollie 我想應該是 null pointer。
3 3 4 Fran 不是,我確認過了。
4 6 13 Kukla 應該要去檢查錯誤資料。
5 7 8 Ollie 對,這是個 bug。
6 9 12 Fran 請加上個檢查。
7 1 11 Kukla 加上去後就好了。
查詢
有了節點左右方的數字後,就可以利用這些數字查詢子樹結構 :
-- comment 4 以及其下層的資料
SELECT c2.* FROM comments AS c1 JOIN comments as c2 ON c2.nsleft BETWEEN c1.nsleft AND c1.nsright WHERE c1.comment_id = 4;
-- 如果已經有 comment 4 的 nsleft/nsright 資料,query 可以簡化成
SELECT * FROM comments WHERE nsleft BETWEEN 6 AND 13;
查詢所有父階資料也沒問題 :
-- comment 6 以及其上層的資料
SELECT c2.* FROM comments AS c1 JOIN comments AS c2 ON c1.nsleft BETWEEN c2.nsleft AND c2.nsright WHERE c1.comment_id = 6;
-- 如果已經有 comment 6 的 nsleft/nsright 資料,query 可以簡化成
SELECT * FROM comments WHERE nsleft <= 9 && nsright >= 12;
修改
刪除節點是 Nested Sets 亮眼的地方,因為 nsleft 和 nsright 的數字其實不會因為數字沒有連續而導致樹狀結構出錯,只要仍然保持 pre order 的順序,所有的 query 都會保持正常。
要刪除一個節點,並將子節點往上提,只需要直接刪除該節點就好:
DELETE FROM comments WHERE comment_id = 6;
刪除一個節點和以下的節點也很簡單,因為已經可以輕易地查詢出子樹狀結構:
DELETE FROM comments WHERE nsleft BETWEEN 6 AND 13;
不過,新增和搬移節點的時候,因為需要維護 pre order 順序,因此這兩種動作就複雜了許多。以在 comment 5 下方新增節點為例:
-- 首先需要把 comment 5 之後的節點,其 nsleft/nsright 的值全部調整一次,好空出 8 和 9 這兩值來
UPDATE comments SET
nsleft = CASE
WHEN nsleft >= 8 THEN nsleft + 2
ELSE nsleft
END,
nsright = nsright+2
WHERE nsright >= 7;
-- 之後才能新增
INSERT INTO comments (nsleft, nsright, bug_id, author, comment_text) VALUES (8, 9, 1234, 'Fran', 'Me too!');
不管新增或搬移,都牽涉到更新許多其他的節點的 nsleft, nsright,操作也較複雜,因此這兩種資料操作是 Nested Sets 的罩門所在。
小結
優點:
- 各類查詢、刪除兩種動作實作簡單,效能也好。
缺點:
- 新增、搬移實作複雜,而且要維護其他節點的
nsleft、nsright,不適合在修改次數頻繁且資料量大的結構使用。 - 較難理解。
Closure Table
Closure Table 是將節點階層關係全部記錄下來的作法,一種空間換取時間的標準例子。這個作法把每一個節點自己和所有子節點的關係記錄在另一張表格,在查詢時當成 intersect table 使用。所以這種作法需要兩張表格:
-- 原本的 comments 表格,不作任何修改
CREATE TABLE comments (
comment_id BIGINT UNSIGNED AUTO_INCREMENT PRIMARY KEY,
bug_id BIGINT UNSIGNED NOT NULL,
author TEXT NOT NULL,
comment_text TEXT NOT NULL,
);
-- 用來紀錄階層關係的新表格
CREATE TABLE comment_tree_paths (
ancestor BIGINT UNSIGNED NOT NULL,
descendant BIGINT UNSIGNED NOT NULL,
PRIMARY KEY(ancestor, descendant),
FOREIGN KEY (ancestor) REFERENCES comments(comment_id),
FOREIGN KEY (descendant) REFERENCES comments(comment_id)
);
表格資料如下 :
comment_id bug_id author comment_text
----------------------------------------------------
1 1234 Fran 為什麼會有這個 bug ?
2 1234 Ollie 我想應該是 null pointer。
3 1234 Fran 不是,我確認過了。
4 1234 Kukla 應該要去檢查錯誤資料。
5 1234 Ollie 對,這是個 bug。
6 1234 Fran 請加上個檢查。
7 1234 Kukla 加上去後就好了。
ancestor descendant
----------------------
1 1
1 2
1 3
1 4
1 5
1 6
1 7
2 2
2 3
3 3
4 4
4 5
4 6
4 7
5 5
6 6
6 7
7 7
comment_tree_paths 這張表格內可以看到每一個節點都有相對應的 descendant 資料,並把自己也當成子節點之一。下圖是節點資料的關係:
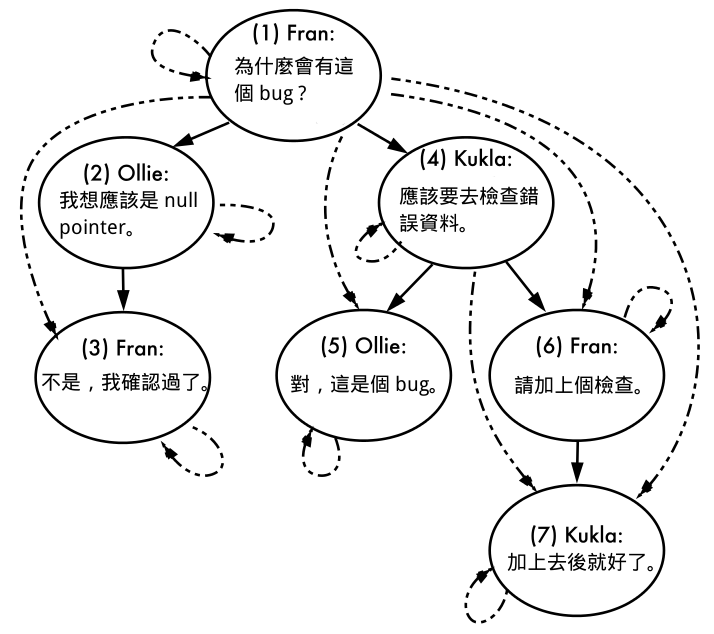
查詢
查詢 comment 4 與其所有子節點:
SELECT c.* FROM comments AS c JOIN comment_tree_paths AS t ON c.comment_id = t.descendant WHERE t.ancestor = 4;
查詢 comment 6 與其所有父節點:
SELECT c.* FROM comments AS c JOIN comment_tree_paths AS t ON c.comment_id = t.ancestor WHERE t.descendant = 6;
修改
新增一筆 comment 到 comment 7 下:
-- 新增 comment
INSERT INTO comments (bug_id, author, comment_text) VALUES (1234, 'Ollie', 'Good job!');
-- 新增 comment_tree_paths 關係
INSERT INTO comment_tree_paths (ancestor, descendant)
SELECT t.ancestor, LAST_INSERT_ID() FROM comment_tree_paths AS t
WHERE t.descendant = 7
UNION ALL
SELECT LAST_INSERT_ID(), LAST_INSERT_ID();
新增 comment_tree_paths 資料的方法是先查詢出有哪些節點的子節點有 comment 7,再用 union 將自己也放進去結果內,最後將查詢的結果一次建立起來。
刪除 comment 4 及之下的所有 comment 時,如果 comment_tree_paths 有設定 ON DELETE CASCADE:
-- 刪除 comment,連同 comment_tree_paths 都一併刪除
DELETE FROM comments WHERE comment_id IN (SELECT descendant FROM comment_tree_paths WHERE ancestor = 4);
或者也可以只刪除關連性,保持原本的 comment 資料
-- 只刪除關連
DELETE FROM comment_tree_paths WHERE descendant IN (
SELECT descendant FROM (SELECT descendant FROM comment_tree_paths WHERE ancestor = 4) AS d
);
搬移節點則需要兩個步驟,假設要將 comment 6 搬到 comment 3:
-- 把除了自己以外,將 comment 6 當成 ancestor 和 descendant 的關連刪除
-- 會刪除 (1, 6), (1,7), (4, 6), (4, 7)
DELETE FROM comment_tree_paths WHERE
descendant IN (
-- 把 comment 6 當成 ancestor 的關連
SELECT descendant FROM (
SELECT descendant FROM comment_tree_paths WHERE ancestor = 6
) AS d
)
AND
ancestor IN (
-- 把 comment 6 當成 descendant 的關連, (6, 6) 除外
SELECT ancestor FROM (
SELECT ancestor FROM comment_tree_paths WHERE descendant = 6 AND ancestor != descendant
) AS a
);
-- 利用 CROSS JOIN 將 comment 6 和 comment 3 的關連產生出來後建立
-- 會建立出 (1, 6), (2, 6), (3, 6), (1, 7), (2, 7), (3, 7)
INSERT INTO comment_tree_paths
SELECT super.ancestor AS super_ancestor, sub.descendant AS sub_descendant FROM comment_tree_paths AS super, comment_tree_paths AS sub
WHERE super.descendant = 3 AND sub.ancestor = 6;
P.S : MySQL 似乎不允許 UPDATE/DELETE 時 reference 自己當條件,因此需要使用 derived table,看起來比較複雜一點。
Closure Table 變型
如果有需要,Closure Table 還能夠透過增加記錄 ancestor 到 descendant 的階層距離,來改善需要針對特定層級拿取資料的查詢
CREATE TABLE comment_tree_paths (
ancestor BIGINT UNSIGNED NOT NULL,
descendant BIGINT UNSIGNED NOT NULL,
path_length INT NOT NULL, -- 新欄位
PRIMARY KEY(ancestor, descendant),
FOREIGN KEY (ancestor) REFERENCES comments(comment_id),
FOREIGN KEY (descendant) REFERENCES comments(comment_id)
);
在此種作法中,下一階的 descendant,距離為 1,下兩階的距離為 2,以此類推。有了這些資料後,可以做如下的查詢:
comment 4 所有下一層 comment :
SELECT c.* FROM comments AS c JOIN comment_tree_paths AS t ON c.comment_id = t.ancestor WHERE ancestor = 4 AND path_length = 1;
comment 1 下三層的 comment :
SELECT c.* FROM comments AS c JOIN comment_tree_paths AS t ON c.comment_id = t.ancestor WHERE ancestor = 1 AND path_length <= 3;
小結
優點:
- 靈活,可以對應絕大部份對樹狀結構的需求。
- 關連資料不在資料本身的表格上,因此關連的方式可以任意使用,利如一筆資料可以出現在不同樹上。
缺點:
- 查詢速度是用空間換出來的。
- 較難理解。
總結
每一種實作的方式都有自己的優缺點,選擇時需要考慮到使用的資料結構適合哪一種方式
- Adjacency List: 最容易實作和理解,如果資料庫有支援 Recursive Query 的話就能夠改善查詢的問題。
- Path Enumeration: 缺點較多,但是需要依賴路徑資料時比其他方便。
- Nested Sets: 適合用在大量查詢為主,偶爾才會修改的資料。
- Closure Table: 最靈活,唯一一個能讓資料被不同結構關連的作法,但需要花費額外空間。